dask.delayed - 并行化任意代码
目录
您可以在实时会话中运行此 notebook,或在Github 上查看它。![]()

dask.delayed - 并行化任意代码¶
如果您没有 array 或 dataframe 怎么办?您无需将函数应用于每个块,而是可以使用 @delayed 装饰器修饰函数,使函数本身成为惰性的。
这是使用 dask 并行化现有代码库或构建复杂系统的简单方法。
相关文档
正如我们在分布式调度器 notebook 中将看到的,Dask 有几种并行执行代码的方法。我们将通过创建一个 dask.distributed.Client 来使用分布式调度器。目前,这将为我们提供一些不错的诊断信息。我们稍后将深入讨论调度器。
[1]:
from dask.distributed import Client
client = Client(n_workers=4)
典型工作流程¶
通常,如果工作流程包含 for 循环,则可以从 delayed 中受益。以下示例概述了一个读取-转换-写入过程
import dask
@dask.delayed
def process_file(filename):
data = read_a_file(filename)
data = do_a_transformation(data)
destination = f"results/{filename}"
write_out_data(data, destination)
return destination
results = []
for filename in filenames:
results.append(process_file(filename))
dask.compute(results)
基础知识¶
首先,我们创建一些玩具函数 inc 和 add,它们会休眠一段时间来模拟工作。然后我们将计时正常运行这些函数的时间。
在下一节中,我们将并行化此代码。
[2]:
from time import sleep
def inc(x):
sleep(1)
return x + 1
def add(x, y):
sleep(1)
return x + y
我们使用 %%time magic 来计时此正常代码的执行时间,这是 Jupyter Notebook 的一个特殊函数。
[3]:
%%time
# This takes three seconds to run because we call each
# function sequentially, one after the other
x = inc(1)
y = inc(2)
z = add(x, y)
CPU times: user 107 ms, sys: 26 ms, total: 133 ms
Wall time: 3 s
使用 dask.delayed 装饰器进行并行化¶
那两个 increment 调用可以并行调用,因为它们完全相互独立。
我们将使用 dask.delayed 装饰器使 inc 和 add 函数成为惰性的。当我们像以前一样通过传递参数调用 delayed 版本时,原始函数实际上尚未被调用——这就是为什么单元格执行速度非常快的原因。相反,会创建一个延迟对象,该对象会跟踪要调用的函数以及要传递给它的参数。
[4]:
import dask
@dask.delayed
def inc(x):
sleep(1)
return x + 1
@dask.delayed
def add(x, y):
sleep(1)
return x + y
[5]:
%%time
# This runs immediately, all it does is build a graph
x = inc(1)
y = inc(2)
z = add(x, y)
CPU times: user 241 µs, sys: 43 µs, total: 284 µs
Wall time: 273 µs
这立即运行了,因为实际上还没有发生任何事情。
要获取结果,请调用 .compute。请注意,这比原始代码运行得更快。
[6]:
%%time
# This actually runs our computation using a local thread pool
z.compute()
CPU times: user 186 ms, sys: 35.8 ms, total: 222 ms
Wall time: 2.14 s
[6]:
5
刚才发生了什么?¶
z 对象是一个惰性的 Delayed 对象。此对象包含了计算最终结果所需的一切,包括对所有必需函数的引用及其输入和相互关系。我们可以像上面一样使用 .compute() 评估结果,或者使用 .visualize() 可视化此值的任务图。
[7]:
z
[7]:
Delayed('add-3602d5e7-31dd-4b69-a059-cabe0549954f')
[8]:
# Look at the task graph for `z`
z.visualize()
[8]:
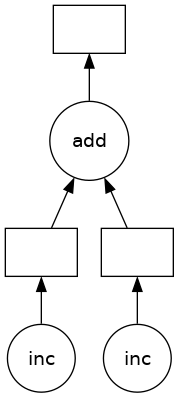
请注意,这包括之前函数的名称,以及 inc 函数的输出到 add 函数输入的逻辑流。
一些需要思考的问题:¶
为什么我们从 3 秒缩短到 2 秒?为什么不能并行化到 1 秒?
如果
inc和add函数不包含sleep(1)会发生什么?Dask 还能加速这段代码吗?如果我们有多个输出或者还想访问 x 或 y 怎么办?
练习:并行化 for 循环¶
for 循环是我们最常想要并行化的事情之一。对 inc 和 sum 使用 dask.delayed 来并行化下面的计算
[9]:
data = [1, 2, 3, 4, 5, 6, 7, 8]
[10]:
%%time
# Sequential code
def inc(x):
sleep(1)
return x + 1
results = []
for x in data:
y = inc(x)
results.append(y)
total = sum(results)
CPU times: user 261 ms, sys: 76.9 ms, total: 338 ms
Wall time: 8.01 s
[11]:
total
[11]:
44
[12]:
%%time
# Your parallel code here...
CPU times: user 3 µs, sys: 1e+03 ns, total: 4 µs
Wall time: 5.72 µs
[13]:
@dask.delayed
def inc(x):
sleep(1)
return x + 1
results = []
for x in data:
y = inc(x)
results.append(y)
total = sum(results)
print("Before computing:", total) # Let's see what type of thing total is
result = total.compute()
print("After computing :", result) # After it's computed
Before computing: Delayed('add-f563d63b41f91fd63da9dec08e1dcb34')
After computing : 44
与直接使用 sum 函数而不是用 delayed 包装的版本相比,图可视化结果如何?你能解释后者的版本吗?你可能会发现以下表达式的结果很有启发性
inc(1) + inc(2)
练习:并行化带有控制流的 for 循环代码¶
通常我们只想延迟部分函数,立即运行其中一些。当这些函数速度很快并帮助我们确定应该调用哪些较慢的函数时,这尤其有用。这个延迟还是不延迟的决定,通常是我们在使用 dask.delayed 时需要仔细考虑的地方。
在下面的示例中,我们遍历一个输入列表。如果输入是偶数,则调用 inc。如果输入是奇数,则调用 double。这个 is_even 判断是否调用 inc 或 double 必须立即做出(而不是惰性),以便我们的图构建 Python 代码可以继续执行。
[14]:
def double(x):
sleep(1)
return 2 * x
def is_even(x):
return not x % 2
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[15]:
%%time
# Sequential code
results = []
for x in data:
if is_even(x):
y = double(x)
else:
y = inc(x)
results.append(y)
total = sum(results)
print(total)
Delayed('add-be32c1dc62a029f9d9b1a55e0be45350')
CPU times: user 183 ms, sys: 32.3 ms, total: 216 ms
Wall time: 5.01 s
[16]:
%%time
# Your parallel code here...
# TODO: parallelize the sequential code above using dask.delayed
# You will need to delay some functions, but not all
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 5.48 µs
[17]:
@dask.delayed
def double(x):
sleep(1)
return 2 * x
results = []
for x in data:
if is_even(x): # even
y = double(x)
else: # odd
y = inc(x)
results.append(y)
total = sum(results)
[18]:
%time total.compute()
CPU times: user 144 ms, sys: 14.9 ms, total: 159 ms
Wall time: 3.04 s
[18]:
90
[19]:
total.visualize()
[19]:
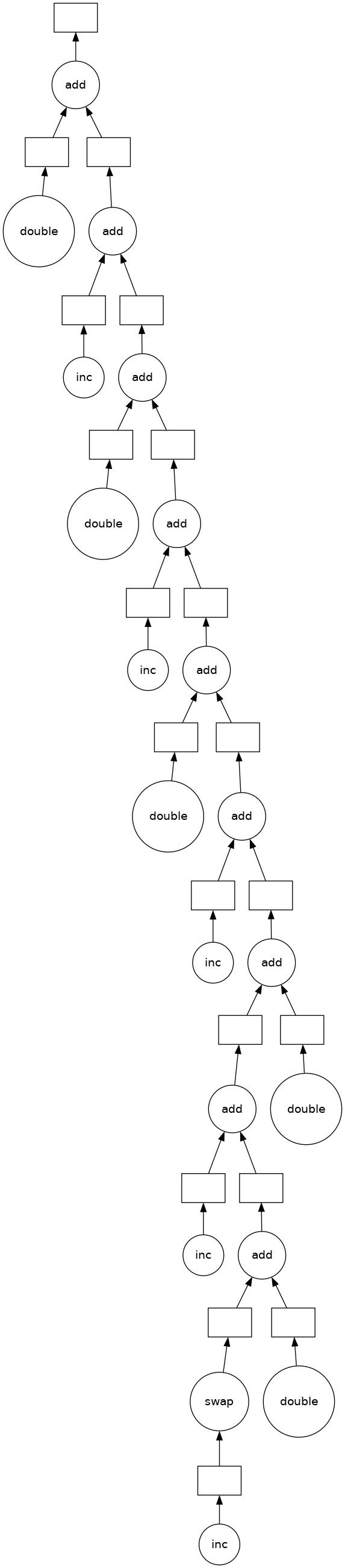
一些需要思考的问题:¶
哪些控制流的例子我们不能使用 delayed?
如果在上面的示例中,我们延迟了
is_even(x)的评估会发生什么?你对延迟
sum有什么看法?这个函数既涉及计算,运行速度也很快。
练习:并行化 Pandas Groupby 归约¶
在本练习中,我们将读取几个 CSV 文件并并行执行 groupby 操作。我们将获得完成此操作的顺序代码,并使用 dask.delayed 对其进行并行化。
我们将要并行化的计算是根据一些历史航班数据计算每个机场的平均出发延迟。我们将使用 dask.delayed 和 pandas 一起完成此操作。在未来的章节中,我们将使用 dask.dataframe 完成相同的练习。
创建数据¶
运行此代码准备一些数据。
这将下载并提取 1990 年至 2000 年间从纽约市出发的一些历史航班数据。数据源自此处。
[20]:
%run prep.py -d flights
检查数据¶
[21]:
import os
sorted(os.listdir(os.path.join("data", "nycflights")))
[21]:
['1990.csv',
'1991.csv',
'1992.csv',
'1993.csv',
'1994.csv',
'1995.csv',
'1996.csv',
'1997.csv',
'1998.csv',
'1999.csv']
使用 pandas.read_csv 读取一个文件并计算平均出发延迟¶
[22]:
import pandas as pd
df = pd.read_csv(os.path.join("data", "nycflights", "1990.csv"))
df.head()
[22]:
| 年份 | 月份 | 月中的日期 | 周中的日期 | 出发时间 | 计划出发时间 | 到达时间 | 计划到达时间 | 唯一承运人 | 航班号 | ... | 飞行时间 | 到达延迟 | 出发延迟 | 出发地 | 目的地 | 距离 | 滑行入位时间 | 滑行出位时间 | 已取消 | 已备降 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1990 | 1 | 1 | 1 | 1621.0 | 1540 | 1747.0 | 1701 | 美国 | 33 | ... | NaN | 46.0 | 41.0 | EWR | PIT | 319.0 | NaN | NaN | 0 | 0 |
| 1 | 1990 | 1 | 2 | 2 | 1547.0 | 1540 | 1700.0 | 1701 | 美国 | 33 | ... | NaN | -1.0 | 7.0 | EWR | PIT | 319.0 | NaN | NaN | 0 | 0 |
| 2 | 1990 | 1 | 3 | 3 | 1546.0 | 1540 | 1710.0 | 1701 | 美国 | 33 | ... | NaN | 9.0 | 6.0 | EWR | PIT | 319.0 | NaN | NaN | 0 | 0 |
| 3 | 1990 | 1 | 4 | 4 | 1542.0 | 1540 | 1710.0 | 1701 | 美国 | 33 | ... | NaN | 9.0 | 2.0 | EWR | PIT | 319.0 | NaN | NaN | 0 | 0 |
| 4 | 1990 | 1 | 5 | 5 | 1549.0 | 1540 | 1706.0 | 1701 | 美国 | 33 | ... | NaN | 5.0 | 9.0 | EWR | PIT | 319.0 | NaN | NaN | 0 | 0 |
5 行 × 23 列
[23]:
# What is the schema?
df.dtypes
[23]:
Year int64
Month int64
DayofMonth int64
DayOfWeek int64
DepTime float64
CRSDepTime int64
ArrTime float64
CRSArrTime int64
UniqueCarrier object
FlightNum int64
TailNum float64
ActualElapsedTime float64
CRSElapsedTime int64
AirTime float64
ArrDelay float64
DepDelay float64
Origin object
Dest object
Distance float64
TaxiIn float64
TaxiOut float64
Cancelled int64
Diverted int64
dtype: object
[24]:
# What originating airports are in the data?
df.Origin.unique()
[24]:
array(['EWR', 'LGA', 'JFK'], dtype=object)
[25]:
# Mean departure delay per-airport for one year
df.groupby("Origin").DepDelay.mean()
[25]:
Origin
EWR 10.854962
JFK 17.027397
LGA 10.895592
Name: DepDelay, dtype: float64
顺序代码:每个机场的平均出发延迟¶
上面的单元格计算了一年内每个机场的平均出发延迟。这里我们使用顺序 for 循环将其扩展到所有年份。
[26]:
from glob import glob
filenames = sorted(glob(os.path.join("data", "nycflights", "*.csv")))
[27]:
%%time
sums = []
counts = []
for fn in filenames:
# Read in file
df = pd.read_csv(fn)
# Groupby origin airport
by_origin = df.groupby("Origin")
# Sum of all departure delays by origin
total = by_origin.DepDelay.sum()
# Number of flights by origin
count = by_origin.DepDelay.count()
# Save the intermediates
sums.append(total)
counts.append(count)
# Combine intermediates to get total mean-delay-per-origin
total_delays = sum(sums)
n_flights = sum(counts)
mean = total_delays / n_flights
CPU times: user 42.6 ms, sys: 9.62 ms, total: 52.2 ms
Wall time: 54.8 ms
[28]:
mean
[28]:
Origin
EWR 12.500968
JFK NaN
LGA 10.169227
Name: DepDelay, dtype: float64
并行化上面的代码¶
使用 dask.delayed 并行化上面的代码。您还需要了解一些额外的事情。
对延迟对象的方法和属性访问会自动工作,因此如果您有一个延迟对象,您可以在其上执行正常的算术运算、切片和方法调用,它将生成正确的延迟调用。
当您有单个输出时,调用
.compute()方法效果很好。当您有多个输出时,您可能希望使用dask.compute函数。这样 Dask 就可以共享中间值。
因此,您的目标是使用 dask.delayed 并行化上面的代码(已复制到下面)。您可能还需要稍微可视化计算过程,看看是否做得正确。
[29]:
%%time
# your code here
CPU times: user 2 µs, sys: 1 µs, total: 3 µs
Wall time: 5.96 µs
如果您加载解决方案,请在单元格顶部添加 %%time 来测量运行时间。
[30]:
%%time
# This is just one possible solution, there are
# several ways to do this using `dask.delayed`
@dask.delayed
def read_file(filename):
# Read in file
return pd.read_csv(filename)
sums = []
counts = []
for fn in filenames:
# Delayed read in file
df = read_file(fn)
# Groupby origin airport
by_origin = df.groupby("Origin")
# Sum of all departure delays by origin
total = by_origin.DepDelay.sum()
# Number of flights by origin
count = by_origin.DepDelay.count()
# Save the intermediates
sums.append(total)
counts.append(count)
# Combine intermediates to get total mean-delay-per-origin
total_delays = sum(sums)
n_flights = sum(counts)
mean, *_ = dask.compute(total_delays / n_flights)
CPU times: user 104 ms, sys: 17.8 ms, total: 122 ms
Wall time: 804 ms
[31]:
(sum(sums)).visualize()
[31]:
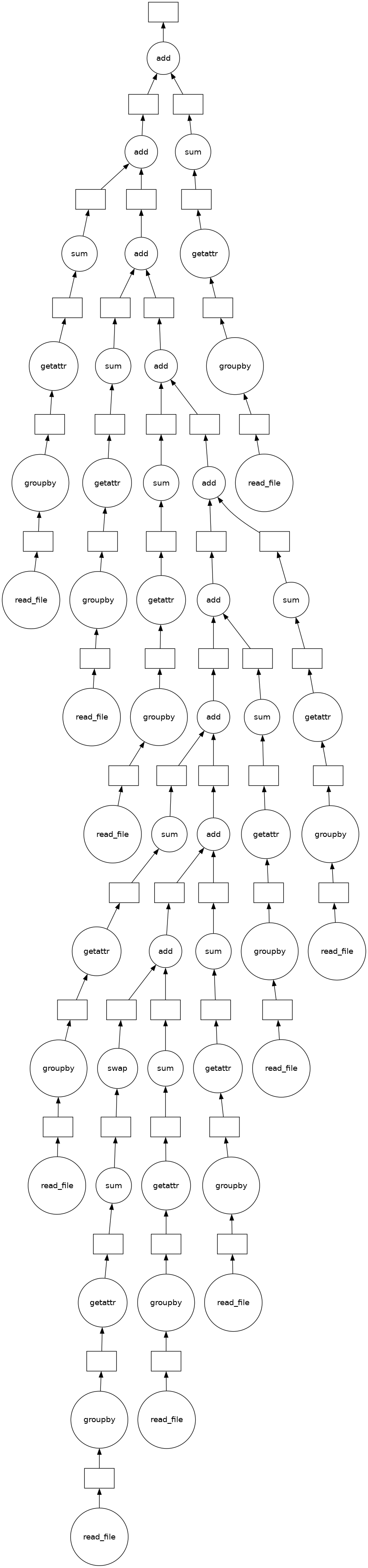
[32]:
# ensure the results still match
mean
[32]:
Origin
EWR 12.500968
JFK NaN
LGA 10.169227
Name: DepDelay, dtype: float64
一些需要思考的问题:¶
您获得了多少加速?这是您期望的加速程度吗?
尝试在哪里调用
compute。当您在sums和counts上调用它时会发生什么?如果您等待并在mean上调用它会发生什么?尝试延迟调用
sum。如果sum被延迟,图看起来像什么?如果它没有被延迟,图看起来像什么?您能想到选择其中一种归约方式而不是另一种的任何原因吗?
了解更多¶
访问 Delayed 文档。特别是,这个delayed 截屏视频将巩固您在这里学到的概念,而delayed 最佳实践文档收集了关于如何用好 dask.delayed 的建议。