欢迎来到 Dask 教程
目录
您可以在在线会话中运行此 notebook ![]() ,或在Github 上查看。
,或在Github 上查看。
欢迎来到 Dask 教程¶

Dask 是一个并行和分布式计算库,可以扩展现有的 Python 和 PyData 生态系统。
Dask 可以充分利用您笔记本电脑的全部容量,也可以扩展到云集群。
一个 Dask 计算示例¶
在下面的代码行中,我们读取 2015 年的纽约市出租车数据并找到平均小费金额。不用担心代码,这只是一个快速演示。我们将在下一个 notebook 中详细介绍所有这些内容。 :)
给学习者的提示:这对于 Binder 来说可能负担较重。
给讲师的提示:不要忘记打开 Dask Dashboard!
[1]:
import dask.dataframe as dd
from dask.distributed import Client
[2]:
client = Client()
client
[2]:
客户端
Client-845b1dac-168d-11ee-8eb8-6045bd777373
| 连接方法: Cluster object | 集群类型: distributed.LocalCluster |
| 仪表盘: http://127.0.0.1:8787/status |
集群信息
LocalCluster
91ea8798
| 仪表盘: http://127.0.0.1:8787/status | 工作节点 2 |
| 总线程数 2 | 总内存: 6.77 GiB |
| 状态: 运行中 | 使用进程: True |
调度器信息
调度器
Scheduler-7976f3a2-3aff-4784-95bb-9426ad30d2e0
| 通信: tcp://127.0.0.1:34735 | 工作节点 2 |
| 仪表盘: http://127.0.0.1:8787/status | 总线程数 2 |
| 启动时间: 刚刚 | 总内存: 6.77 GiB |
工作节点
工作节点: 0
| 通信: tcp://127.0.0.1:38123 | 总线程数 1 |
| 仪表盘: http://127.0.0.1:41927/status | 内存: 3.38 GiB |
| Nanny: tcp://127.0.0.1:43723 | |
| 本地目录: /tmp/dask-worker-space/worker-x071ar75 | |
工作节点: 1
| 通信: tcp://127.0.0.1:45859 | 总线程数 1 |
| 仪表盘: http://127.0.0.1:35955/status | 内存: 3.38 GiB |
| Nanny: tcp://127.0.0.1:37341 | |
| 本地目录: /tmp/dask-worker-space/worker-c88ae90u | |
[3]:
ddf = dd.read_parquet(
"s3://dask-data/nyc-taxi/nyc-2015.parquet/part.*.parquet",
columns=["passenger_count", "tip_amount"],
storage_options={"anon": True},
)
[4]:
result = ddf.groupby("passenger_count").tip_amount.mean().compute()
result
[4]:
passenger_count
0 1.590343
1 1.752130
2 1.705595
3 1.579748
4 1.459269
5 1.728534
6 1.680769
7 3.863473
8 5.060718
9 5.075917
Name: tip_amount, dtype: float64
什么是 Dask?¶
“Dask” 项目包含多个部分:* 集合/API,也称为“核心库”(core-library)。* 分布式(Distributed)—— 用于创建集群 * 集成和更广泛的生态系统
Dask 集合¶
Dask 为大于内存的数据集提供多核和分布式+并行执行
我们可以将 Dask 的 API(也称为集合)视为具有高层和低层两种级别

高层集合: Dask 提供了高层的 Array、Bag 和 DataFrame 集合,它们模仿 NumPy、list 和 pandas,但可以在不适合内存的数据集上并行操作。
低层集合: Dask 还提供了低层的 Delayed 和 Futures 集合,让您可以更好地控制构建自定义并行和分布式计算。
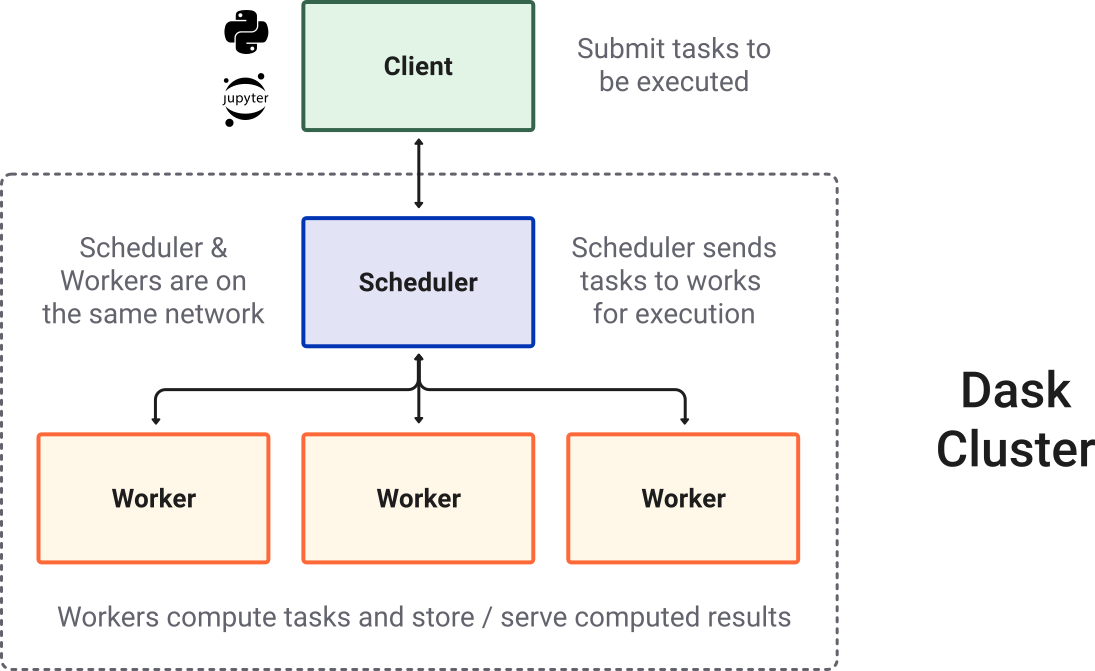
Dask 生态系统¶
除了核心 Dask 库及其分布式调度器外,Dask 生态系统还连接了其他一些项目,包括
Dask-ML(并行 scikit-learn 风格 API)
Dask-image
Dask-cuDF
Dask-sql
Dask-snowflake
Dask-mongo
Dask-bigquery
内置 Dask 集成的社区库,例如
Xarray
XGBoost
Prefect
Airflow
Dask 部署库 - Dask-kubernetes - Dask-YARN - Dask-gateway - Dask-cloudprovider - jobqueue
… 当我们谈论 Dask 项目时,我们将所有这些努力视为社区的一部分。
准备¶
git clone http://github.com/dask/dask-tutorial
然后安装必要的包。有三种不同的方法可以实现这一点,选择最适合您的一种,并且只选择一个选项。它们按优先级顺序排列如下
在主仓库目录下
conda env create -f binder/environment.yml
conda activate dask-tutorial
您将需要以下核心库
conda install -c conda-forge ipycytoscape jupyterlab python-graphviz matplotlib zarr xarray pooch pyarrow s3fs scipy dask distributed dask-labextension
请注意,这些选项将更改您的现有环境,可能会改变您已安装包的版本。
教程结构¶
每个部分都是一个 Jupyter notebook。包含文本、代码和练习的混合内容。
概述 - dask 在整个生态系统中的位置。
Dataframe - 在分布于集群中的多个 pandas dataframes 上进行并行化操作。
Array - 阻塞式的类似 numpy 的功能,处理分布在集群中的 numpy 数组集合。
Delayed - 一种并行化通用 python 代码的单一函数方式。
部署/分布式 - Dask 用于集群的调度器,包含如何查看 UI 的详细信息。
分布式 Futures - 非阻塞式结果,异步计算。
结论
如果您没有使用过 Jupyterlab,它与 Jupyter Notebook 类似。如果您没有使用过 Notebook,快速介绍如下:
有两种模式:命令模式和编辑模式
在命令模式下,按
Enter进入编辑单元格(就像这个 markdown 单元格)在编辑模式下,按
Esc切换到命令模式按
shift+enter执行单元格并移动到下一个单元格。
工具栏有执行、转换和创建单元格的命令。
练习:打印 Hello, world!¶
每个 notebook 都会有供您解决的练习。您会看到一个空白或部分完成的单元格,后面跟着一个包含解决方案的隐藏单元格。例如。
打印文本“Hello, world!”。
[5]:
# Your code here
下一个单元格包含解决方案。单击省略号展开解决方案,并且务必运行解决方案单元格,以防 notebook 后面的部分依赖于解决方案的输出。
[6]:
print("Hello, world!")
Hello, world!
有用链接¶
参考
寻求帮助
Stack Overflow 上关于用法问题的
`dask<http://stackoverflow.com/questions/tagged/dask>`__ 标签用于报告错误和提出功能请求的github issues
用于一般性非 bug 问题和讨论的discourse forum
参加在线教程