Dask 数组 - 并行化的 numpy
目录
您可以在 实时会话 中运行此 notebook ![]() 或在 Github 上查看。
或在 Github 上查看。

Dask 数组 - 并行化的 numpy¶
使用分块算法实现的并行、大于内存的 n 维数组。
并行:使用计算机上的所有核心
大于内存:通过将数组分解成许多小块,以最大限度地减少计算的内存占用量的方式对这些块进行操作,并有效地从磁盘流式传输数据,使您能够处理大于可用内存的数据集。
分块算法:通过执行许多较小的计算来执行大型计算。

换句话说,Dask 数组使用分块算法实现了 NumPy ndarray 接口的一个子集,将大数组切割成许多小数组。这使我们能够使用所有核心在大于内存的数组上进行计算。我们使用 Dask 图来协调这些分块算法。
在本 notebook 中,我们将从头开始实现一些分块算法,从而建立一些理解。然后,我们将使用 Dask 数组,利用熟悉的 NumPy 风格的 API,并行地分析大型数据集。
相关文档
启动客户端¶
[2]:
from dask.distributed import Client
client = Client(n_workers=4)
client
[2]:
客户端
客户端-a8584d52-168d-11ee-91ab-6045bd777373
| 连接方法: 集群对象 | 集群类型: distributed.LocalCluster |
| 仪表板: http://127.0.0.1:8787/status |
集群信息
本地集群
ec3c008b
| 仪表板: http://127.0.0.1:8787/status | 工作节点 4 |
| 总线程数 4 | 总内存: 6.77 GiB |
| 状态: 运行中 | 使用进程: True |
调度器信息
调度器
调度器-1691ff53-cd1c-4181-b6cb-96c87eeb44a0
| 通讯地址: tcp://127.0.0.1:40157 | 工作节点 4 |
| 仪表板: http://127.0.0.1:8787/status | 总线程数 4 |
| 启动时间: 刚刚 | 总内存: 6.77 GiB |
工作节点
工作节点:0
| 通讯地址: tcp://127.0.0.1:34639 | 总线程数 1 |
| 仪表板: http://127.0.0.1:39937/status | 内存: 1.69 GiB |
| Nanny: tcp://127.0.0.1:35069 | |
| 本地目录: /tmp/dask-worker-space/worker-ks5lewlh | |
工作节点:1
| 通讯地址: tcp://127.0.0.1:37259 | 总线程数 1 |
| 仪表板: http://127.0.0.1:40035/status | 内存: 1.69 GiB |
| Nanny: tcp://127.0.0.1:39739 | |
| 本地目录: /tmp/dask-worker-space/worker-af8meok4 | |
工作节点:2
| 通讯地址: tcp://127.0.0.1:36755 | 总线程数 1 |
| 仪表板: http://127.0.0.1:41255/status | 内存: 1.69 GiB |
| Nanny: tcp://127.0.0.1:42443 | |
| 本地目录: /tmp/dask-worker-space/worker-paiuy8ao | |
工作节点:3
| 通讯地址: tcp://127.0.0.1:45703 | 总线程数 1 |
| 仪表板: http://127.0.0.1:40881/status | 内存: 1.69 GiB |
| Nanny: tcp://127.0.0.1:35731 | |
| 本地目录: /tmp/dask-worker-space/worker-8_k1zy69 | |
分块算法简介¶
我们来比较一下使用 NumPy 数组和 Dask 数组计算数组元素之和。
[3]:
import numpy as np
import dask.array as da
[4]:
# NumPy array
a_np = np.ones(10)
a_np
[4]:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
我们知道可以使用 sum() 计算数组元素的总和,但为了展示分块操作是什么样的,我们来做
[5]:
a_np_sum = a_np[:5].sum() + a_np[5:].sum()
a_np_sum
[5]:
10.0
现在请注意,上述计算中的每个求和是完全独立的,因此可以并行完成。要使用 Dask 数组实现这一点,我们需要定义我们的“切片”,我们通过使用变量 chunks 定义每个块所需的元素数量来做到这一点。
[6]:
a_da = da.ones(10, chunks=5)
a_da
[6]:
|
||||||||||||||||
重要!
注意,这里为了获得两个块,我们指定 chunks=5,换句话说,每个块有 5 个元素。
[7]:
a_da_sum = a_da.sum()
a_da_sum
[7]:
|
||||||||||||||||
任务图¶
一般来说,人类编写的代码依赖于编译器或解释器,以便计算机能够理解我们所写的内容。当我们转向并行执行时,有一种倾向是将责任从编译器转移到人类,因为他们经常将代码的分析、优化和执行带入代码本身。在这些情况下,我们通常将程序的结构显式地表示为程序内部的数据。
在 Dask 中,我们使用任务调度,将程序分解成许多中等大小的任务或计算单元。我们将这些任务表示为图中的节点,如果一个任务依赖于另一个任务产生的数据,则在节点之间存在边。我们调用任务调度器以尊重这些数据依赖性并尽可能利用并行性的方式执行此图,以便可以同时运行多个独立任务。
[8]:
# visualize the low level Dask graph using cytoscape
a_da_sum.visualize(engine="cytoscape")
[8]:
[9]:
a_da_sum.compute()
[9]:
10.0
性能比较¶
我们来尝试一个更有趣的例子。我们将创建一个 20_000 x 20_000 的具有正态分布值的数组,并计算其沿其中一个轴的平均值。
注意
如果您在 Binder 上运行,由于内存问题,Numpy 示例可能需要更小。
Numpy 版本¶
[10]:
%%time
xn = np.random.normal(10, 0.1, size=(30_000, 30_000))
yn = xn.mean(axis=0)
yn
CPU times: user 33.3 s, sys: 14.9 s, total: 48.2 s
Wall time: 1min 42s
[10]:
array([ 9.99946016, 9.99980906, 9.99989634, ..., 9.99961139,
10.00024232, 9.99993349])
Dask 数组版本¶
[11]:
xd = da.random.normal(10, 0.1, size=(30_000, 30_000), chunks=(3000, 3000))
xd
[11]:
|
||||||||||||||||
[12]:
xd.nbytes / 1e9 # Gigabytes of the input processed lazily
[12]:
7.2
[13]:
yd = xd.mean(axis=0)
yd
[13]:
|
||||||||||||||||
[14]:
%%time
xd = da.random.normal(10, 0.1, size=(30_000, 30_000), chunks=(3000, 3000))
yd = xd.mean(axis=0)
yd.compute()
CPU times: user 1.01 s, sys: 216 ms, total: 1.23 s
Wall time: 18.7 s
[14]:
array([10.00035706, 9.99967479, 9.99930285, ..., 10.00055537,
9.99987736, 10.00016919])
思考题
如果 Dask chunks=(10000,10000),会发生什么?
如果 Dask chunks=(30,30),会发生什么?
练习
对于 Dask 数组,计算 x 数组与其转置之和沿 axis=1 的平均值。
[15]:
# Your code here
解答
[16]:
x_sum = xd + xd.T
res = x_sum.mean(axis=1)
res.compute()
[16]:
array([19.99975576, 19.99908653, 19.99866271, ..., 20.00150558,
19.99986709, 20.00017954])
选择合适的分块大小¶
本节的灵感来自 Genevieve Buckley 的 Dask 博客文章,您可以在此处阅读
刚开始使用 Dask 数组时的一个常见问题是确定什么是好的分块大小。但是什么是好的大小,我们又如何确定呢?
了解分块¶
我们可以将 Dask 数组看作一个由较小尺寸的块组成的巨大结构,这些块通常是单个 numpy 数组,它们被组织起来形成一个更大的 Dask 数组。
如果您有一个 Dask 数组,并想了解有关分块及其大小的更多信息,可以使用 chunksize 和 chunks 属性访问这些信息。如果您在 jupyter notebook 中,还可以通过其 HTML 表示形式可视化 Dask 数组。
[17]:
darr = da.random.random((1000, 1000, 1000))
darr
[17]:
|
||||||||||||||||
请注意,当我们创建 Dask 数组时,我们没有指定 chunks。Dask 默认设置为 chunks='auto',它可以适应理想的分块大小。要了解有关自动分块如何工作的更多信息,您可以访问此文档 https://docs.dask.org.cn/en/stable/array-chunks.html#automatic-chunking
darr.chunksize 显示最大的分块大小。如果您期望数组具有均匀的分块大小,这是分块大小信息的一个很好的摘要。但是如果您的数组具有不规则的分块,darr.chunks 将显示 Dask 数组沿所有维度所有分块的明确大小。
[18]:
darr.chunksize
[18]:
(255, 255, 255)
[19]:
darr.chunks
[19]:
((255, 255, 255, 235), (255, 255, 255, 235), (255, 255, 255, 235))
让我们修改示例,进一步探索分块。我们可以重新分块我们的数组
[20]:
darr = darr.rechunk({0: -1, 1: 100, 2: "auto"})
[21]:
darr
[21]:
|
||||||||||||||||
[22]:
darr.chunksize
[22]:
(1000, 100, 167)
[23]:
darr.chunks
[23]:
((1000,),
(100, 100, 100, 100, 100, 100, 100, 100, 100, 100),
(167, 167, 167, 167, 167, 165))
练习
当在某个轴上指定分块为 -1 时,它有什么作用?
太小是问题¶
如果您的分块太小,每个任务实际完成的工作量非常小,协调所有这些任务的开销会导致效率非常低的过程。
一般来说,Dask 调度器协调单个任务大约需要一毫秒。这意味着我们希望计算时间相对较大,即在秒级别。
Genevieve Buckley 的直观类比
让我们想象一下,我们在建造一栋房子。这是一项相当大的工作,如果只有一个工人,建造时间会非常长。所以我们有一个工人团队和一个工地工头。工地工头相当于 Dask 调度器:他们的工作是告诉工人需要做什么任务。假设我们有一大堆砖头用来砌墙,放在建筑工地的角落里。如果工头(Dask 调度器)让工人们一次只去搬一块砖,然后将每块砖带到砌墙的地方,你可以看到这将非常缓慢和低效!工人们大部分时间都花在墙壁和砖堆之间来回奔波上。很少的时间用于砌砖的实际工作。相反,我们可以用更聪明的方式来做。工头(Dask 调度器)可以告诉工人们每次去搬一整车砖回来。现在工人花在墙壁和砖堆之间来回奔波的时间大大减少,墙壁将更快地完成。
太大是问题¶
如果您的分块太大,这也是一个问题,因为您很可能会耗尽内存。您将在仪表板中看到数据正在溢出到磁盘,这将导致性能下降。
如果我们加载太多数据到内存,Dask 工作节点会开始将数据溢出到磁盘以避免崩溃。将数据溢出到磁盘会显著减慢速度,因为磁盘会产生额外的读写操作。这绝对是我们想要避免的情况,要警惕这种情况,您可以查看仪表板上的工作节点内存图。橙色条是接近内存限制的警告,灰色表示数据正在溢出到磁盘——这可不好!
要警惕这种情况,请查看 Dask 仪表板上的工作节点内存图。橙色条是接近内存限制的警告,灰色表示数据正在溢出到磁盘——这可不好!有关更多提示,请参阅下面关于使用 Dask 仪表板的部分。要了解有关内存图的更多信息,请查阅仪表板文档。
经验法则¶
用户报告说小于 1MB 的分块大小通常表现不佳。一般来说,分块大小在 100MB 到 1GB 之间是好的,而超过 1 或 2GB 则意味着您拥有非常大的数据集和/或每个工作节点拥有大量可用内存。
上限:避免非常大的任务图。超过 10,000 或 100,000 个分块可能会开始表现不佳。
下限:为了获得并行化的优势,您需要的分块数量至少等于可用的工作核心数量(或者更好,是工作核心数量的两倍)。否则,一些工作节点将保持空闲。
计算每个任务所需的时间应远大于调度任务所需的时间。Dask 调度器协调单个任务大约需要 1 毫秒,因此一个好的任务计算时间应该在秒级别(而不是毫秒)。
分块应与磁盘上的数组存储对齐。现代 NDArray 存储格式(HDF5, NetCDF, TIFF, Zarr)允许数组以分块方式存储,以便高效地拉取数据块。然而,数据存储通常比 Dask 数组理想的分块更细,因此常见的做法是选择一个分块大小是存储分块大小的倍数,否则可能会产生很高的开销。例如,如果您加载的数据以 (100, 100) 的块大小进行分块存储,那么您可能会选择像 (1000, 2000) 这样的分块策略,它更大但仍可被 (100, 100) 整除。
有关分块的更多建议,请参阅https://docs.dask.org.cn/en/stable/array-chunks.html
使用 Zarr 进行分块数据的示例¶
Zarr 是一种用于存储分块、压缩的 N 维数组的格式。Zarr 提供了用于处理行为类似于 NumPy 数组(Dask 数组行为类似于 Numpy 数组)的 N 维数组的类和函数,但其数据被分割成块,并且每个块都经过压缩。如果您已经熟悉 HDF5,那么 Zarr 数组提供了类似的功能,但具有一些额外的灵活性。
更多资料请查阅Zarr 教程
我们从 zarr 中读取一个数组
[24]:
import zarr
[25]:
a = da.from_zarr("data/random.zarr")
[26]:
a
[26]:
|
||||||||||||||||
请注意,该数组已经分块,并且我们在加载时没有指定任何内容。现在请注意,这些分块的大小不错,我们来计算平均值并看看运行需要多长时间
[27]:
%%time
a.mean().compute()
CPU times: user 86.9 ms, sys: 13 ms, total: 99.9 ms
Wall time: 770 ms
[27]:
0.49993442200099847
我们加载另一个示例,其中 chunksize 小得多,看看会发生什么
[28]:
b = da.from_zarr("data/random_sc.zarr")
b
[28]:
|
||||||||||||||||
[29]:
%%time
b.mean().compute()
CPU times: user 19.9 s, sys: 1.51 s, total: 21.4 s
Wall time: 53.6 s
[29]:
0.49995306804346007
练习:¶
在读取 b 时提供一个 chunksize,以改善平均值计算所需的时间。尝试多个 chunks 值,看看会发生什么。
[30]:
# Your code here
[31]:
# 1 possible Solution (imitate original). chunks will vary if you are in binder
c = da.from_zarr("data/random_sc.zarr", chunks=(6250000,))
c
[31]:
|
||||||||||||||||
[32]:
%%time
c.mean().compute()
CPU times: user 59.9 ms, sys: 22.9 ms, total: 82.7 ms
Wall time: 1.12 s
[32]:
0.49995306804346035
Xarray¶
在某些应用中,我们有多维数据,有时处理所有这些维度可能会令人困惑。Xarray 是一个开源项目和 Python 包,它使得处理带标签的多维数组更加容易。
Xarray 的灵感来源于并大量借鉴了 pandas,后者是一个专注于带标签表格数据的流行数据分析包。它特别适合处理 netCDF 文件(这是 xarray 数据模型的来源),并与 Dask 紧密集成用于并行计算。
Xarray 在原始的 NumPy 式数组之上引入了维度、坐标和属性形式的标签,这使得开发体验更加直观、简洁且不易出错。
我们来学习如何一起使用 xarray 和 Dask
[33]:
import xarray as xr
[34]:
ds = xr.tutorial.open_dataset(
"air_temperature",
chunks={ # this tells xarray to open the dataset as a dask array
"lat": 25,
"lon": 25,
"time": -1,
},
)
ds
[34]:
<xarray.Dataset>
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 dask.array<chunksize=(2920, 25, 25), meta=np.ndarray>
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...[35]:
ds.air
[35]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
dask.array<open_dataset-air, shape=(2920, 25, 53), dtype=float32, chunksize=(2920, 25, 25), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ][36]:
ds.air.chunks
[36]:
((2920,), (25,), (25, 25, 3))
[37]:
mean = ds.air.mean("time") # no activity on dashboard
mean # contains a dask array
[37]:
<xarray.DataArray 'air' (lat: 25, lon: 53)> dask.array<mean_agg-aggregate, shape=(25, 53), dtype=float32, chunksize=(25, 25), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
[38]:
# we will see dashboard activity
mean.load()
[38]:
<xarray.DataArray 'air' (lat: 25, lon: 53)>
array([[260.37564, 260.1826 , 259.88593, ..., 250.81511, 251.93733,
253.43741],
[262.7337 , 262.7936 , 262.7489 , ..., 249.75496, 251.5852 ,
254.35849],
[264.7681 , 264.3271 , 264.0614 , ..., 250.60707, 253.58247,
257.71475],
...,
[297.64932, 296.95294, 296.62912, ..., 296.81033, 296.28793,
295.81622],
[298.1287 , 297.93646, 297.47006, ..., 296.8591 , 296.77686,
296.44348],
[298.36594, 298.38593, 298.11386, ..., 297.33777, 297.28104,
297.30502]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0标准的 Xarray 操作¶
我们来获取 air 变量并进行一些操作。使用 xarray 对象的操作是相同的,无论底层数据是存储为 Dask 数组还是 NumPy 数组。
[39]:
dair = ds.air
[40]:
dair2 = dair.groupby("time.month").mean("time")
dair_new = dair - dair2
dair_new
[40]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53, month: 12)> dask.array<sub, shape=(2920, 25, 53, 12), dtype=float32, chunksize=(2920, 25, 25, 1), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0 * lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0 * time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00 * month (month) int64 1 2 3 4 5 6 7 8 9 10 11 12
当您希望结果是数据存储为 NumPy 数组的 xarray.DataArray 时,调用 .compute() 或 .load()。
[41]:
# things happen in the dashboard
dair_new.load()
[41]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53, month: 12)>
array([[[[-5.14987183e+00, -5.47715759e+00, -9.83168030e+00, ...,
-2.06136017e+01, -1.25448456e+01, -6.77099609e+00],
[-3.88607788e+00, -3.90576172e+00, -8.17987061e+00, ...,
-1.87125549e+01, -1.11448669e+01, -5.52117920e+00],
[-2.71517944e+00, -2.44839478e+00, -6.68945312e+00, ...,
-1.70036011e+01, -9.99716187e+00, -4.41302490e+00],
...,
[-1.02611389e+01, -9.05839539e+00, -9.39399719e+00, ...,
-1.53933716e+01, -1.01606750e+01, -6.97190857e+00],
[-8.58795166e+00, -7.50210571e+00, -7.61483765e+00, ...,
-1.35699463e+01, -8.43449402e+00, -5.52383423e+00],
[-7.04670715e+00, -5.84384155e+00, -5.70956421e+00, ...,
-1.18162537e+01, -6.54209900e+00, -4.02824402e+00]],
[[-5.05761719e+00, -4.00010681e+00, -9.17195129e+00, ...,
-2.52222595e+01, -1.53296814e+01, -5.93362427e+00],
[-4.40733337e+00, -3.25991821e+00, -8.36616516e+00, ...,
-2.44294434e+01, -1.41292725e+01, -5.66036987e+00],
[-4.01040649e+00, -2.77757263e+00, -7.87347412e+00, ...,
-2.40147858e+01, -1.34914398e+01, -5.78581238e+00],
...
-3.56890869e+00, -2.47412109e+00, -1.16558838e+00],
[ 6.08795166e-01, 1.47219849e+00, 1.11965942e+00, ...,
-3.59872437e+00, -2.50396729e+00, -1.15667725e+00],
[ 6.59942627e-01, 1.48742676e+00, 1.03787231e+00, ...,
-3.84628296e+00, -2.71829224e+00, -1.33132935e+00]],
[[ 5.35827637e-01, 4.01092529e-01, 3.08258057e-01, ...,
-1.68054199e+00, -1.12142944e+00, -1.90887451e-01],
[ 8.51684570e-01, 8.73504639e-01, 6.26892090e-01, ...,
-1.33462524e+00, -7.66601562e-01, 1.03210449e-01],
[ 1.04107666e+00, 1.23202515e+00, 8.63311768e-01, ...,
-1.06607056e+00, -5.31036377e-01, 3.14453125e-01],
...,
[ 4.72015381e-01, 1.32940674e+00, 1.15509033e+00, ...,
-3.23403931e+00, -2.23956299e+00, -1.11035156e+00],
[ 4.14459229e-01, 1.23419189e+00, 1.07876587e+00, ...,
-3.47311401e+00, -2.56188965e+00, -1.37548828e+00],
[ 5.35278320e-02, 8.10333252e-01, 6.73461914e-01, ...,
-4.07232666e+00, -3.12890625e+00, -1.84762573e+00]]]],
dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
* month (month) int64 1 2 3 4 5 6 7 8 9 10 11 12使用 xarray 进行时间序列操作¶
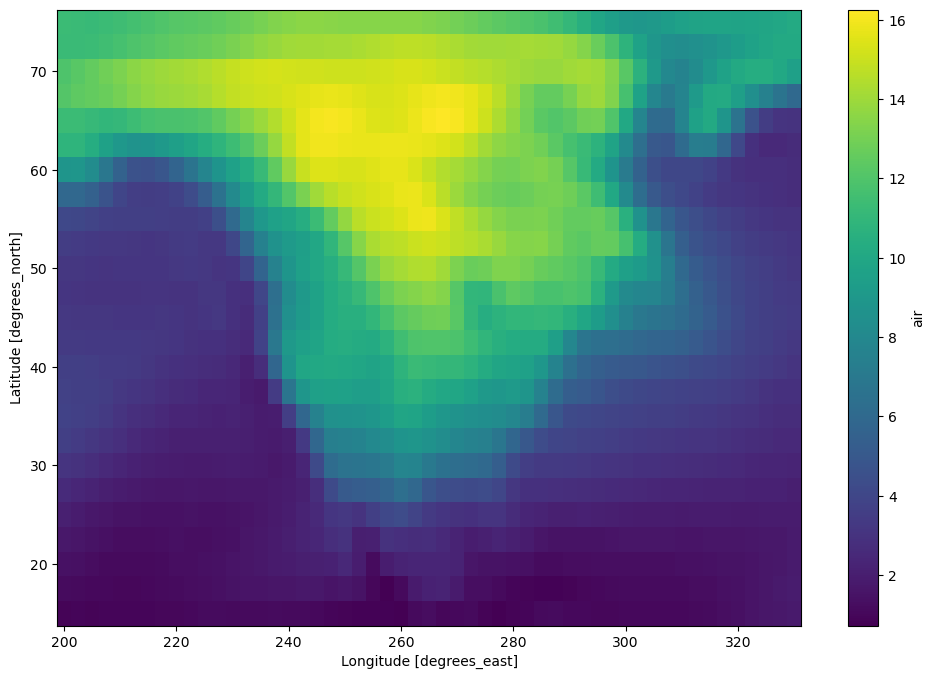
由于我们有一个日期时间索引,时间序列操作可以高效地工作,例如我们可以进行重采样然后绘制结果。
[42]:
dair_resample = dair.resample(time="1w").mean("time").std("time")
[43]:
dair_resample.load().plot(figsize=(12, 8))
[43]:
<matplotlib.collections.QuadMesh at 0x7f5dec7fea40>